To understand AWS Global Infrastructure, consider the coffee shop. If an event such as parade, flood or power outage impacts one location, customers can still get their coffee by visiting a different location only a few blocks away. This is similar to how AWS Global Infrastructure works.
AWS Regions
When determining the right Region for the services, data and application, consider the following 4 business factors :
- Compliance with data governance and legal requirements : depending on company and location, company might need to run its data out of specific areas. For example, if company requires all of its data to reside within the boundaries of UK, London Region will be chosen
- Proximity to customers : selecting a region that is close to the customers will help to get the content to them faster. For example, the company is based in Washington, DC, and many of customers live in Singapore. Company might consider running an infrastructure in the Northern Virginia Region to be close to company headquarters, and run application from the Singapore Region
- Available services within a Region : sometimes the closest Region may not have all the features company wants to offer to customers. Suppose that developers want to build an application that uses Amazon Braket (AWS quantum computing platform). Amazon Braket is not yet available in every AWS Region around the world, so developers will have to run it in one of the Regions that already offers it
- Pricing : suppose that company is considering running applications in both the United States and Brazil. In Brazil it can cost 50% more to run the same workload
Availability Zones
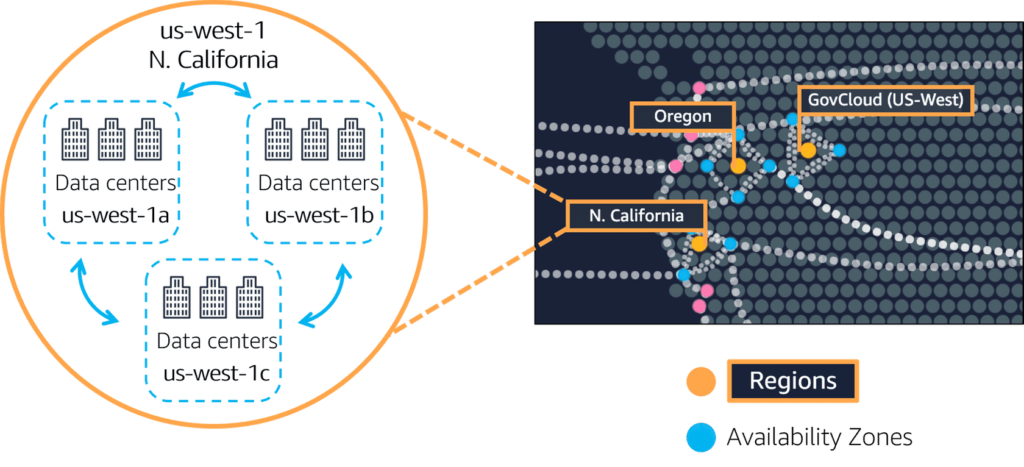
An Availability Zone is a single data center or a group of data centers within a Region. Availability Zones are located tens of miles apart from each other. This is close enough to have low latency (the time between when content requested and received) between Availability Zones. However, if a disaster occurs in one part of the Region, they are distant enough to reduce the chance that multiple Availability Zones are affected
Planning for failure and deploying applications across multiple Availability Zones is an important part of building a resilient and highly available architecture.
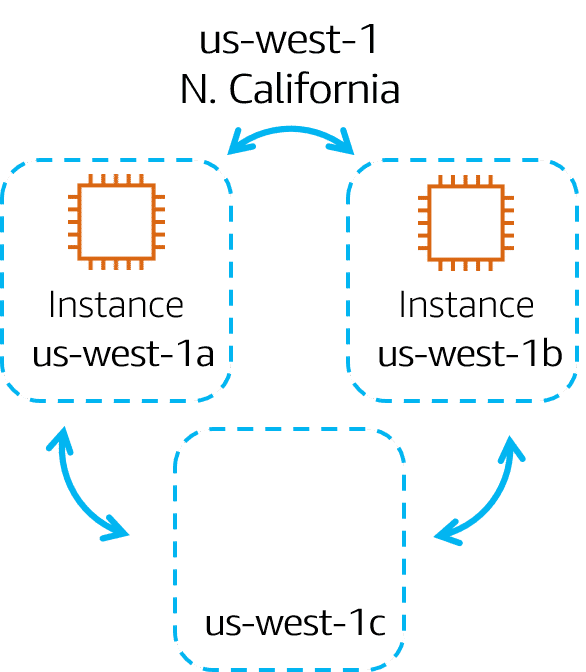
Suppose that company is running an application on a single Amazon EC2 instance in the Northern California Region. The instance is running in the us-west-1a Availability Zone. If us-west-1a were to fail, company would lose its instance. A best practice is to run applications across at least two Availability Zones in a Region. If us-west-1a were to fail, application would still be running in us-west-1b