Big Data is a collection of large datasets that cannot be processed using traditional computing techniques. It is not a single technique or a tool, rather it has become a complete subject, which involves various tools, techniques and frameworks.
Big Data includes huge volume, high velocity and extensible variety of data. The data in it will be of three types :
- Structured data – relational data
- Semi Structured data – XML data
- Unstructured data – Word, PDF, Text, Media Logs
There are various technologies in the market from different vendors including Amazon, IBM, Microsoft etc., to handle big data. Generally technologies divide on two classes :
- Operational Big Data – systems like MongoDB that provide operational capabilities for real-time, interactive workloads where data is primarily captured and stored. NoSQL Big Data systems are designed to take advantage of new cloud computing architecture that have emerged to allow massive computations to be run inexpensively and efficiently. This makes operational big data workloads much easier to manage, cheaper, and faster to implement
- Analytical Big Data – systems like Massively Parallel Processing (MPP) database systems and MapReduce that provide analytical capabilities for retrospective and complex analysis that may touch most of all the data. MapReduce provides a new method of analyzing data that is complementary to the capabilities provided by SQL, and also provides a system based on MapReduce that can be scaled up from single servers to thousands of high and low end machines
These two classes of technology are complementary and frequently deployed together.
Operational vs Analytical Systems :
| Operational | Analytical | |
| Latency | 1 ms – 100 ms | 1 min – 100 min |
| Concurrency | 1_000 – 100_000 | 1- 10 |
| Access Pattern | Writes and Reads | Reads |
| Queries | Selective | Unselective |
| Data Scope | Operational | Retrospective |
| End User | Customer | Data Scientist |
| Technology | NoSQL | MapReduce, MPP Database |
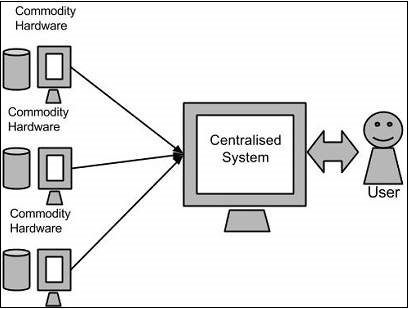
In traditional approach, an enterprise will have a computer to store and process big data. For storage purpose, the programmers will take the help of their choice of database vendors such as Oracle, IBM, etc. In this approach, the user interacts with the application, which in turn handles the part of data storage and analysis :
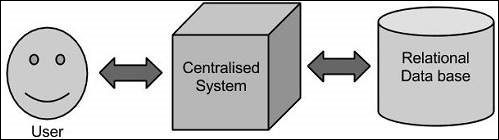
This approach works fine with those applications that process less voluminous data that can be accomodated by standard database servers, or up to the limit of the processor that is processing the data. But when it comes to dealing with the huge amounts of scalable data, it is a hectic task to process such data through a single database bottleneck.
Google solved this problem using an algorithm called MapReduce. This algorithm divides the task into small parts and assigns them to many computers, and collects the results from them which then integrated, from the result dataset :